|
An Axiomatic Model of Information Presentation
Gary Perlman
|
Table of Contents
|
| Paper originally published in Proceedings of the Human Factors Society 31st Annual Meeting, 1987, 1229-1233, Santa Monica, CA: Human Factors Society. Republished in Perlman, Green, & Wogalter (Eds.) Human Factors Perspectives on Human-Computer Interaction, 1995, 120-124, Santa Monica, CA: HFES. |
The work presented here tries to formalize the rules we use to design effective information displays based on information structure. It is concentrated on visual information displays, but the methods may apply as well to other media, such as acoustic presentations of information.
Monochrome video enhancements like reverse video, underlining, different intensity and blinking, and color enhancements are very salient. With judicious use of these enhancements, users can find specific items among hundreds almost as quickly as if the items were displayed alone. For example, if only a few fields on a screen are in reverse video or blinking, then they can be found almost immediately. Similar effects can be observed for graphics displays that can present different type faces and font sizes. We should expect that any model of information presentation should apply equally well to printed media as to computer displays.
The lack of use of boxes or region-separating lines is another limitation of Tullis' model. Boxes (or window panes) are used to separate and highlight distinct items or groups of items, in many cases without the loss of display space. The combination of boxing and video attributes is used in almost every modern display. Boxing is such an attractive display alternative, that Tullis himself could not avoid using it in his sample display of an improved narrative display (1985), even though his own program misinterpreted the meaning of the box, identifying it as a separate group.
Any analysis of screen display quality must be able to work with these highly effective techniques of coding and discrimination.
It is unrealistic to assume that people would try to use and evaluate a display without considering its content. For example, if we know that there are many items to display on a screen, and that they must appear in a particular order, such as in many data entry forms, then most random orderings would produce unacceptable displays, but perfectly acceptable to Tullis' analysis.
Designers need kibbitzers that describe problematic regions of displays and prescribe remedies. To spot problem regions, or in extreme cases, disaster areas, a designer's aide must know the intentions of the designer (the structure of the information to be displayed), and the methods available to the designer to convey that structure (e.g., the video attributes, graphics, and positional controls).
PERSONAL Name: __________________________ (Last, First, ...) Sex: _ (M or F) Birthdate: __/__/__ (mm/dd/yy) SSN: ___-__-____ Citizenship: ________ HOME INFORMATION Address: _____________________________ Apt: _____ City: ___________________ State: __ Zip: _____ Phone: (___) ___-____ WORK INFORMATION Title: ___________________ Dept: _______________ Company: __________________________________________ Address: __________________________________________ City: ___________________ State: __ Zip: _____ Phone: (___) ___-____ Ext: _____ Email: __________________________________________After seeing so many forms like this, it is hard to consciously notice all the relations of component parts. I will first describe them informally. The form has three sections: PERSONAL data, HOME address information, and WORK address information. Each section has subparts, so the form is a hierarchical structure. The sections are partially ordered -- PERSONAL data is first, and the order of the WORK and HOME data does not matter. The subparts of the major parts of the form, or fields as they are usually called, have their own structure. Each field has a label followed by a colon, and a fill-in area of some maximum size. The fill-in areas in a section tend to be aligned in columns. A fill-in area may contain punctuation delimiting further subdivisions and there may be a comment or example at the end of the field to help guide data entry and interpretation. There are recurring fields and groups of fields, like the City-State-Zip fields in the HOME and WORK sections. Some fields are repeated, but with exceptions; the HOME address has a field for apartment number, and the WORK phone number has a field for extension.
Now I will show how the structure of information in the form can be represented. Later I will show how differences and similarities among units of information can be mapped to differences and similarities in display. There are the following relations in the form:
X in Y the item X is part of Y X isa Y X is an instance of Y X after Y X must follow after Y X is P X has some property PTo represent this information structure, I use semantic networks (Quillian, 1968) because of their ability to represent graphs with different relations among nodes. The basic data structures in a semantic network are nodes and arcs between nodes. Here, nodes represent items of information, and arcs represent relations between items of information. Uppercase names will be used to denote items in an information structure. Lowercase names will be used to denote types (such as dates) that are defined elsewhere. Literal text is in quotes. A prefix notation list structure will be used to denote relations between items. For example, if X is part of Y, I will write:
(in X Y)and when there is no ambiguity, I will also write:
(X in Y)More properly, in a semantic network notation, (X in Y) means to point from X to Y with an arc labeled in:
(point X Y in).Also, when there is no ambiguity, I will write multiple statements in one statement by adding multiple parameters around relations. For example:
(X Y Z in W)is read as X and Y and Z are all in W. In some cases, to avoid notation that contains details of programming languages, I will use English.
To describe parts of the example display, we must write many statements describing relations. For each item in the form, we need to indicate what it is contained in, its type, and a display string (such as a prompt for a field).
Next I declare that a field has a label, and a fill-in part, and that they must be in that order.
(label fillin in field) (fillin after label)
(":" entry-area in fillin)
Putting the colon as part of the
fillin
part of a field
makes sense because it is the prompt for the data entry area.
Next I say that the string "Name" is the label for the NAME field,
("Name" isa label, in NAME)
and define the
fillin
part of the field in
NAME.
((len 30) "(Last, ...)" isa fillin, in NAME)
When types are defined, they can be given properties that are inherited by all instances of these types. For example, by saying that BIRTH isa date. and defining what a date is, we encapsulate and reuse the structural properties of dates.
("Birthdate" isa label, in BIRTH)
(month day year in birth)
(year after day after month)
(month day year isa number)
((len 2) "/" ... isa fillin, in date)
To represent the rest of the form takes declarations like the following.
(HOME WORK after PERSONAL)
("Home Information" isa label, in HOME)
("Work Information" isa label, in WORK)
(HADDRESS HAPT HCSZ HPHONE in HOME)
(HADDRESS HAPT HPHONE isa field)
(WTITLE WDEPT ... WEMAIL in WORK)
(WTITLE WDEPT ... WEMAIL isa field)
Note how the
City-State-Zip
part of each field is identical in
the
HOME
and
WORK
parts.
In a display, we would want them to be displayed analogously,
and the way to do this is to define a type that contains
the common parts.
(HCSZ WCSZ isa csz)
(city state zip isa field, in csz)
(zip after state after city)
("City" isa label, in city)
("State" isa label, in state)
("Zip" isa label, in zip)
...
(HAPT isa apt)
(apt after address)
("Address isa label, partof address)
Once the structure of the information to be displayed has been represented, we can predict sources of complexity based on cognitive psychological principles, before we even begin to consider how that information will be displayed. This is important because we need to be able to evaluate the complexity of the display with respect to the complexity of the information to be displayed. For any display, there must be some minimum possible perceptual complexity based on the information structure to be displayed. Further complexity is added by suboptimal display design. Sometimes, a designer will try to put too much information, so that there is no acceptable layout. In such a case, redesigning the information presentation is hopeless; it is the information itself that must be redesigned. We can look at the number of structures at any level in a hierarchy that are to be displayed. Research such as Miller (1956) suggests that this number, which we may call the branching factor in this context should be kept within a 7 +/- 2 limit for many displays, but which should be traded off against potential hierarchical depth (Kiger, 1984).
If we assume that distinct top level groups are separated by blank space, then we are in a good position to use Tullis' regression models, because we know (1) the number of groups, (2) their sizes, (3) the number of items, and (4) the overall density. The particulars of item placement would affect item uncertainty and local density. This points out that much of Tullis' analysis is directed at figuring out what the designer should already know.
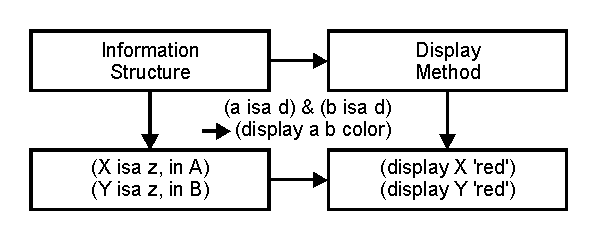
There are several more general axioms of information presentation, but I will now turn to a specialized axiom, or rule, for a particular display. In the example form, I display section titles in all uppercase letters, at the top and to the left of each section's region. Here is a rule for doing part of this.
In the example form, structure is presented using display methods like position, alignment, upper and mixed case. I use spatial location to distinguish major sections of the form, alignment to show position of labels and fillins in fields, and similar formats to show similar structures (e.g., City-State-Zip).
Rather than use spatial separation to display personal, work, and home information, different regions could separate different types of data (e.g., addresses in one, phone numbers in another, etc.). This would produce an unsatisfactory display because it creates too many top level groups. This shows that in any automated system, we must provide designers with control over how general rules are applied.
Designers also need control when there are no rules to apply. I have no rule for when unrelated items may occupy the same line (e.g., Sex and Birthdate), so designers need the capability to place specific fields (ie. to attach specific display attributes to specific items). Note that there are rules that make City, State, and Zip items appear on the same line. Those fields are part of a specially defined structure so they can share a feature (the same line, or perhaps the same color).
Once a display is designed, the system has a kibbitzing component that looks for problems. It complains if it cannot find a display attribute to distinguish different items, and to a lesser extent if it cannot find common attributes for similar items. The similarity analysis is based on Tversky (1977). Because the general kibbitzer is not too smart, the screen display kibbitzer also complains about more mundane violations, such as sub-units being outside the physical region of a unit, or overlapping units.
With more experience with the model I hope to build a flexible system for a more common environment such as an IBM PC. Another goal is to be able to connect it to a runtime library of display routines, so that inferred changes of attribute assignments to structural patterns can be viewed interactively.
====================== Personal ===================== |NAME: .......................... (LAST, FIRST, ...)| |SEX: . (M OR F) CITIZENSHIP: ........ | |SSN: ...-..-.... BIRTHDATE: ../../.. (MM/DD/YY)| ================== Work Information ================= |TITLE: ................... DEPT: ...............| |COMPANY: ..........................................| |EMAIL: ..........................................| |ADDRESS: ..........................................| |CITY: ................... STATE: .. ZIP: .....| |PHONE: (...) ...-.... EXT: ..... | ================== Home Information ================= |ADDRESS: ............................. APT: .....| |CITY: ................... STATE: .. ZIP: .....| |PHONE: (...) ...-.... | =====================================================
We need to be able to represent intentions of designers to determine goodness of a display. Such intentions are representable, at least in part, as the relations and properties of items in the display.
We need rules to map information structure into display attributes; these rules and a system for their application would be an expert system for display design. An eventual goal is to develop rules that allow automated (at least good first approximations of) presentations of complex information structures, much as database report generators can be used to automate displays of relational data. We need to be able to override expert system choices.
We need to be able to adapt display designs to different devices such as character displays, graphics displays, and even auditory displays. Any model of information display that does not use display device capabilities (or lack thereof) as display parameters will have limited applicability.
We need intelligent kibbitzers to tell us where we may be making mistakes or creating catastrophes and how to avoid them, suggesting alternatives and perhaps tradeoffs. Weighted averages are misleading evaluations because of their limited diagnostic and prescriptive abilities. We need to be able to tell kibbitzers that their advice has been noted but ignored, such as when we decide that it is acceptable that a window overlay obscures part of a screen, or we will always have to search for new complaints among the old.