Gary Perlman
School of Information Technology
Wang Institute of Graduate Studies
Tyngsboro, MA 01879 USA
(617) 649-9731
May 1986
Table of Contents
An early version of this paper was presented at the ACM SIGDOC Fourth International Conference on Systems Documentation in Ithaca, NY, June 1985.
The philosophy behind multilingual programming is that software development must deal evenhandedly with all parts of software products if high quality software is going to be developed economically. The high cost of software is not due to the difficulty of coding, but in recoding and redocumenting software. Many expressions of the same ideas must be constructed and coordinated. Program code and comments, user interface and on-line help, and a variety of off-line documents, all must be consistent. A solution to the coordination problem is presented in this paper. Multilingual programming is a method of developing software that uses a database of information to generate multiple target languages like commented program code, user interface languages, and text formatting languages.
The method begins with an analysis of a domain to determine key attributes. These are used to describe particular problems in the domain and the description is stored in a database. Attributes in the database are inserted in idiomatic templates for a variety of target languages to generate solutions to the original problem. Because each of these solutions is based on the same source database of information, the solutions (documents, programs, etc.) are consistent. If the information changes, the change is made in the database and propagated to all solutions. Conversely, if the form of a solution must change, then only the templates change. The method saves much effort for updates of documents and programs that must be coordinated by designing for redesign.
Keywords: Automatic Program Generation, Automatic Documentation, User Interface, Language Design
There are many types of text associated with software:
A program is designed and written. Comments are inserted into the program. Preliminary documentation for the program is written, and users give feedback to the developers. New features are put in the program, and some, but not all, of the comments in the code are updated. Some prompts and error messages in the user interface are not changed to reflect the workings of the new program. New documentation is written, after which some user interface prompts are modified. The product is shipped to market.
I contend that the problems of accuracy and consistency can be traced to the wasted dual efforts of programmers and documenters. Traditionally, documentation by programmers have been viewed as inefficient for several reasons:
This paper presents some practical solutions to the problem
of accuracy and consistency of documentation.
I will not talk about documentation separated from the issues of
programming, user interfaces, or on-line help.
These problems must be addressed with a coordinated effort.
With the following examples, I hope to convey the diverse applications of multilingual programming (MLP) by showing its use in a variety of domains. The technique can be summarized as follows: We begin with analysis of the problem domain, breaking it into small parts. Then we use this analysis to describe a particular problem. At that point, there is an abstract description of the problem. We then synthesize the description into a solution. Because we have a point at which a problem is described abstractly, we can synthesize several solutions.
While the above is abstract, it can be further summarized as analysis followed by multiple syntheses. In the following examples, this pattern is the one to watch for. The method will be formalized later.
UNIX|STAT (Perlman, 1980) is a compact data analysis system developed at the University of California, San Diego, and at the Wang Institute of Graduate studies. It runs on the UNIX (Ritchie & Thompson, 1974) and MSDOS operating systems. anova, a UNIX|STAT program, does a general analysis of variance. For non-statistically trained people, that means it is used primarily for analyzing data collected from experiments with controlled factors. Traditional ANOVA programs (Dixon, 1975; Nie et al, 1975) require that data be input as a matrix and the description of the experimental design information is in a special language separate from the data. In my experience, this method of experimental design specification leads to confusion and errors when used by inexperienced analysts. The anova program was designed to read self-documented input and from that, infer the structural relationships (the experimental design) in the data.
Each input line to anova contains one datum preceded by the names of the level of factors at which that datum was obtained. For example, suppose we have an experiment testing the effectiveness of two display formats, B&W and color, to two classes of readers, young and old. We present both formats to each reader, and measure comprehension on a percentage scale. Some of the data might look like this:
BamBam B&W young 52 BamBam color young 78 Fred color old 25 Fred B&W old 75 Pebbles color young 83 Pebbles B&W young 65 Wilma B&W old 93 Wilma color old 58anova takes this analysis and infers the experimental design by synthesis. There are several points worth noting in the data.
The idea behind the anova program is to remove tedious and error prone tasks from data analysts by providing a synthesis of analysis. Given this design information, much of the data analysis process can be automated and verified (Perlman, 1982).
The ANOVA example shows how a simple input, a relational database containing records describing individual data points, can produce a complex output, automating many details.
The references to this paper are stored in a simple database. The format for a record looks something like this:
author = Perlman G article = An Eye For an Eye For an Arm and a Leg journal = Journal of Irreproducible Results date = 1981 issue = 4 pages = 29-30Records are extracted from a central database and sorted before being formatted for input to the troff text formatting system (Kernighan, Lesk, & Ossanna, 1974). There are several types of publication records in the database: books, journal articles, articles in edited books, technical reports, and so on. For each publication type, a different format is required. The references in this paper are printed in APA format (APA, 1983). Two properties of the formatting might change: the output format, or the text formatter. For example, the ACM uses a different format, and Scribe (Reid & Walker, 1980) and TEX (Knuth, 1979) are other text formatters. With my personal database system, it is a simple translation of one format to another, or of one formatter to another. Templates defining how the records (analysis) are formatted (synthesis) are simply redefined.
Again stepping back for an overview, this is an example of analyzing a problem into simple parts that are placed in a relational database with sparse records, and synthesizing several different solutions. The solutions here are different reference formats using different text formatting systems. A more general view is that there are multiple views of a database by using a flexible report generation capability.
S is a system and language for data analysis (Becker & Chambers, 1984). While at Bell Labs, I developed a high-level user interface to the S language using the IFS (Vo, 1985) user interface language. S is a large system, with over 300 functions, each with about 3-6 options. The system I built (Perlman, 1983) has a screen with a form and a menu for every S function; the menu controls the invocation of the function and the form allows users to supply options. There are over 100 menus arranged in a hierarchy to help users find the functions of interest. In all, there are close to 500 screens, each with menus or forms, and on-line help. In developing this system, I pushed the idea of MLP to new limits, and found it was more powerful than I had anticipated.
It was clear to me that programming 500 screens by hand, even with a high level language like IFS, was going to present problems. User interface design is an iterative process, and if each iteration involved changing hundreds of files containing screen descriptions, then it would be impossible to make many changes. Early in the development, I decided to design a special purpose artificial language (Perlman, 1984) especially suited to designing screens in the IFS language. An artificial language is a special purpose notation for precise and concise communication within a limited domain. My goal was to be able to specify the screen designs with as little syntax as possible. In the words of Tufte (1983), I wanted to minimize the ``ink to data'' ratio and specify only the information that changed from screen to screen. I did not want to repeatedly specify the formatting information because it would have wasted my time and made it more difficult to maintain consistency.
Becker and Chambers had already done much of my work by designing the S interface language using the m4 macro processor (Kernighan & Ritchie, 1980). The S interface language defines attributes of S functions and their options. The most notable are the attributes of options including:
ARG (main, OPTIONAL, CHAR)In English, the main title of the plot is an optional character vector with no default value.
Missing from the information in the S interface language is on-line help about the purpose of the functions and options. I had to add this information from the S documentation by hand to build the high level interface. Once this was done, all the information about the S functions was parameterized (analyzed) and centralized.
The generation of the screens is straightforward, but there are many details. For each function in an S interface language source file, there is a definition of its name, purpose, etc., and the attributes of its options. This is a relational database of information about each function and their options. From this information, m4 macros are defined to parse the information so that it is available to a code generator. The code generator takes this information and extracts what it needs for different parts of the screen design. The following parts are generated:
The code generation can be summarized as follows. Several sources of information are integrated into one consistent database. Information from this database is parsed with m4 and used to fill in the blanks of idiomatic templates (ie. macro definitions) in the IFS language. The same information is used more than once, for help, validation, and for declarations, but each datum comes from one source, thus ensuring consistency.
The result of using m4 macros to design and build the IFS/S interface was beneficial many times over.
Because the IFS code was separated from the database pf function descriptions, macros could be written to generate text in other languages. Full and quick reference paper documents were created using the troff text formatter, each in a few hours. There was no problem of the accuracy of these documents because they were generated from the same source as the user interface, which was generated from the program code. There was no problem with the consistency of these documents, again because they were all generated with the same macros. Such standardization is especially impressive with such a large system and such detailed documents (one was about 100 pages).
The generation of hundreds of thousands of lines of code and several document types is made practical by using the same methods as before: several target languages are generated from a relational database of many records. Given the size of the system, what is particularly impressive is that the user interface and documents are highly consistent and are still flexible; a localized change to the generators changes the whole system uniformly. There is a strong relation between MLP and fourth generation/application generators (Horowitz, et al, 1985; Raghavan & Chand, 1986). With little specification, multiple products (programs, tables, documents) can be generated, although, unlike MLP, these tend to be application specific and less flexible.
SETOPT is a code generator that produces a parser to handle UNIX program command line options (Perlman, 1985). UNIX program options are wildly inconsistent (Norman, 1981), and the efforts of Hemenway & Armitage (1984) to define a syntax standard were accompanied by the development of SETOPT to help develop compliant programs. In addition to ensuring a consistent syntax for command line options, SETOPT deals with on-line help, type checking, input conversions, and range checking. In short, SETOPT aids all aspects of programming command line options on UNIX.
With SETOPT, each option is described with a list of attributes in a format convenient for input to m4 (Kernighan & Ritchie, 1980), a macro processor. For example, a simple text formatting program might take options to control the width of lines, whether lines are numbered, and page headers. With SETOPT, the following could specify these options.
OPT (w, width, Line Width, INT, 0, 72, value>0)
OPT (n, number, Line Numbering, LGL, 0, FALSE)
OPT (h, header, Page Header, STRING, 0, "",
length(value) < optval(width))
This analysis of the options states
that the
width
option is an
integer
of dimension
0
(a scalar)
whose default value is
72
and whose minimum value is
0.
It is set with the
-w
flag, and its purpose is to set the
line width.
Note in the previous English explanation how the
parameters of the
OPT
macro can be plugged into a
troff
(Kernighan, Lesk & Ossanna, 1978)
template to provide detail.
The same information is used by SETOPT to generate a
C
language
(Kernighan & Ritchie, 1979) parser for handling all aspects of the
users interface:
Again, the process is the same as with the other examples. A domain of application is chosen and analyzed so that the problems in the domain are parameterized. This is the analysis stage. This information is in a database from which several solutions can be synthesized. The synthesis is done by plugging information from the database into templates in different languages: with SETOPT, troff macros to generate UNIX manual entries, and C program code to produce a user interface.
The manual entries generated by SETOPT are not complete, nor what I would call great prose. SETOPT provides a simple scheme to insert explanatory text in different parts of the generated document. It is difficult, but not impossible, to generate smoothly flowing text. Computer program documentation, especially that on program option attributes, does not need to read like great prose. This seems to be a domain where tables are superior to plain text, and where consistency, or in another view, monotony, is desired.
The method used in SETOPT is like the previous examples. Simple descriptions of options (problems) are parsed into an accessible format (database) and used repeatedly in each of several target languages: option parser, on-line help, and manual entry. Some software developers fear standards because they can not be sure that the standard will not change. With MLP, programmers can conform to a standard without knowing the rules of the standard. They can be protected against changes in a standard because their only interface is to the database, and the record formats (attributes of options) are stable almost to the point of never changing. It is the code/document generators that contain information about standards and changes to a standard can be encoded centrally. There is a strong analogy with user interface tool development. In the development of user interface management systems, there are two user interfaces: one between the programmer and the user interface tool, and one between the tool and the end-user (Perlman, 1983). With user interface tools, it is easier to standardize the programmer-tool interface than the tool-user interface where new input/output technology and individual differences between users require more flexibility (Perlman, 1985).
Surveys for gathering information can be described with a simple grammar. In an electronic survey system (Perlman, 1985), survey questions are represented as having four basic attributes:
Rate on a scale from minimum to maximum...
Based on these parameters, a question database is constructed, and from it, C program code (Kernighan & Ritchie, 1979) is generated to administer the survey. By changing the templates from which the program code is generated, troff text formatting commands are used instead to generate a paper survey. Some work was done to generate a form based survey system using the Rapid/USE prototyping tool (Wasserman, 1979). Once again, several different synthetic solutions to problems are formed from the same analysis.
By now the recurring themes of the examples should be clear,
and we are ready to formalize the characteristics of the
method of multilingual programming.
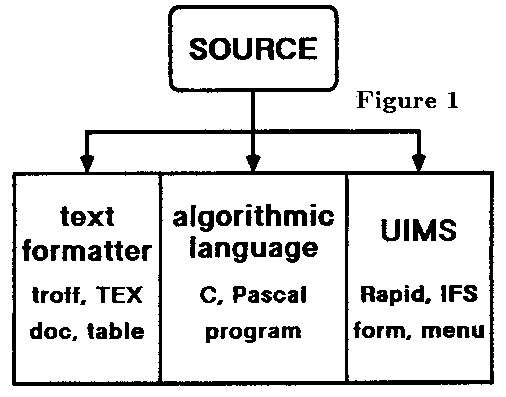
Each of the previous five examples show the same process, depicted in Figure 1. First, an abstraction of a domain is used to analyze a problem. This analysis results in a source database of information representing the problem from which solutions can be constructed by synthesis. The information is plugged into idiomatic templates to generate instances in several classes of target languages: text formatters, report generators, programming languages, and user interface management systems; hence the name multilingual programming. For each class of target language, there are several possible specific languages. The results of the syntheses can include program code, program comments, user interface code, on-line documentation, and off-line documentation. In this section, I will attempt to describe MLP more formally.
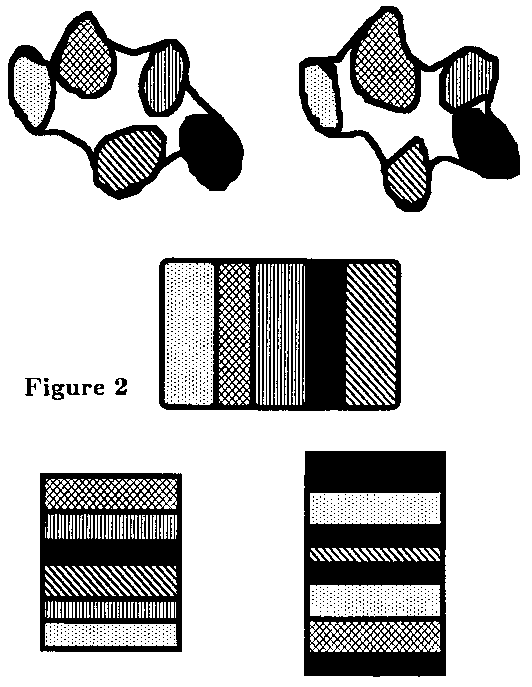
Figure 2 is a graphical representation of the process of MLP. At the top of the Figure are two shapes representing instances in a specific subject domain. An analysis of the instances shows that each has five key concepts in the domain. This pattern is formalized and the information from those five key concepts is extracted and parameterized in a relational database (depicted in the center of Figure 2) to form one source of the information. From this database, several different views or solutions are possible, each being a synthesis of the information in the database, shown at the bottom of Figure 2.
It is not necessary that all information in the database be used in forming a synthetic view. In declaring variables in a programming language, a help string is not necessary, although it is customary to put that information in comments next to the code that is generated. The synthesis on the lower right of Figure 2 does not contain the information shaded with vertical lines.
It is possible to use the same information (always from the same source) more than once. In generating printed documentation, it is a good idea to provide several levels of detail:
When real systems are being developed, these views evolve through an iterative elaboration and refinement process. Consider the development of a user interface system. The templates might begin by scavenging an existing piece of code, parameterizing some parts. A first generation user interface might not check ranges of input values. A second generation user interface might check ranges, but not provide diagnostic error messages. The flexibility of MLP allows developers to address unanticipated needs flexibly and gradually work toward a better system. Note that all the while, the consistency of the system is maintained by generating text based on a single database with the same templates. Change is localized in the templates, thus minimizing effort.
In describing Figure 2, I did not tell how one would notice that several instances share common concepts. I do not know how this can be done in general, except by experience. It was only after writing the troff text commands to format hundreds of references that I noticed I was wasting my time doing the same action repeatedly and that changes in format would be difficult. With experience with similar tasks, a person's performance improves, which is a hint that repeated actions can be automated. There are some psychological theories of how people judge similarity (Tversky, 1977) and how we use analogy (Rumelhart & Norman, 1981) to discover patterns, but no practical methods are known.
A
template
is an abstraction of an idiomatic pattern of text
that frequently occurs in a specific target language
like a text formatting or programming language.
Templates have slots where variables are inserted
to form instances in the target language.
For example,
in the
C
programming language,
a programmer might begin defining the square root function like this:
The information from the previous example
can be parameterized by analysis using a set of attributes:
It can be difficult to write text,
especially phrases, like the
purpose
and
comment
above, because the same information will have to
fit
into many templates.
There is some virtue in the difficulty,
because it forces using consistent formats
(e.g., the tense and voice of all phrases must agree).
Once information is in a database,
many views of the database are possible.
It is only by changing the definitions of the views,
by modifying or substituting the templates,
that different target languages can be generated.
Each target language is based on the
same source of information, and so is consistent with the others.
It is not mandatory that macros be used when building templates.
There are several reasons why macros are preferable to
more common language extensions like functions,
and more common language generators like a high-level language.
Code generators, especially macro processors like
m4,
are not without their problems.
The Quoting Problem.
Recursive evaluation of macros
makes the quoting problem difficult to master.
It can take a long time to learn how to get
nested recursive macros substituted (to avoid quoting)
and how to delay or stop the substitution (to use quoting).
It takes macro programmers a long time to understand the problem
and learn habits that circumvent the problem.
Pretty Printing.
The output from text generators is often syntactically correct
for the target language,
but an ugly sight to the human eye.
The output from macro substitutions contain everything
in the definitions of the macros.
This includes any white space to make the
macro definitions more readable.
Unlike most programming languages,
structured macro writing style conflicts with functionality,
especially for templates of text formatting languages
for later human viewing.
The solution seems to be to use a post-processor,
a prettyprinter,
to reformat the macro processor output
for input to a target language processing system.
Often, this involves stripping off
leading space on lines and removing blank lines.
The following quote from Chapter 5 of Whitehead (1911) leads into
one advantage of MLP.
A small change in a program,
such as changing the type of a variable from an integer to a real
should not require a huge effort.
Most current practice requires many changes:
MLP is resilient
to changes of standards and software tools.
Personal experience taught me this well.
While working on a system written in a user interface language,
the definition of the user interface language changed,
leaving me with hundreds of thousands of lines of unworking code.
Because I had generated the user interface language from a database,
I avoided many hours of work by some minor changes to some templates.
Much of the documentation
and many program comments I read
are inaccurate.
This could be attributed to carelessness,
but I think that would avoid confronting the problem.
Text (comments and manuals) written about other text (program code),
by hand,
is going to lag behind, and updates can be forgotten.
Also, text written about other text,
by hand,
can be inaccurate because people make different inferences
from the same information.
MLP promotes accuracy
by automating the updates and removing chances for misinterpretation.
Once a document (user interface) exists,
it meets or sets a standard format for related documents (software).
The format of related documents (user interfaces)
should be consistent so that people can learn based on their
experience, not in spite of it.
Analogy is a powerful human learning mechanism
(Rumelhart & Norman, 1981),
and we should take advantage of it.
Finally, MLP supports abbreviation.
Information in a database is about as abbreviated as possible,
this information is
crossed,
in the Cartesian set theoretical sense,
with templates for each language,
thereby multiplying productivity.
Hester, Parnas, & Utter (1981)
suggest that documentation of systems should precede any development,
and others have suggested that user interfaces should be designed first.
The motivation for writing documentation first is to
write correct code efficiently,
and the motivation for writing user interface specifications first
is to ensure that programs are easy to use.
These are good motivations,
but show how good ideas can compete for attention.
The solution is to work on both problems at the same time
by analyzing the problem so that documentation,
user interfaces, code, and so on,
are treated as equally important parts of software
products that require coordination.
There are problems with choosing a target language,
documentation, programming, user interface, or whatever,
as the source of information for other target languages.
For example,
writing documentation from program code is error prone
and expensive.
When target languages are used as source databases,
they are almost always strained to accommodate the other languages.
For example,
the writing style tools of the Writer's Workbench
(Frase, 1983; Macdonald, 1983)
use
troff
text formatting macros as a text structuring language
and try to infer structure based on formatting instructions.
This is the opposite of the desired process,
that format should reflect content.
Much of the time, inferring structure from formatting language works well,
especially if writers use a particular high level set of macros
developed at Bell Labs,
but sometimes writers find themselves trying to fool
the analysis tools.
It does not make sense to put one part of a programming system
over another.
Neither a good program with poor documentation
nor a bad program with good documentation
are acceptable.
The implementation of programs,
the development of user interfaces,
the writing of documentation,
all must be coordinated.
Knuth (1982) developed the WEB system that combines program code with
structured program comments so that both can be extracted for
input to his TEX formatter (Knuth, 1979)
or just the program code can be extracted for the compiler.
It is a system for printing beautiful program listings
with minimum programmer effort.
While this process is similar to the one described here,
the WEB system does not use analysis of problem domains to
the same extent,
nor does it allow for the use of parameterized information
for domains outside programming,
like documentation and user interfaces.
Natural language systems such as those of Schank (1979)
are able to generate paraphrases of their inputs
in several languages.
Although an impressive feat,
the hard part,
according to Schank,
is to understand the original input
and represent it in a data structure.
Once that is done,
the generation of paraphrases works on the same principle
as in this paper.
In the examples described here,
the problems of parsing the input are trivial compared
to those faced by cognitive scientists studying natural language understanding.
In this final section,
I try to answer
when multilingual programming pays off.
MLP requires planning on a larger scale than is customary.
To implement that plan,
there is the overhead of learning about generating templates.
To offset that cost, there have to be benefits.
MLP is especially suited to large projects
or ones where a coordinated solution is desired.
Suppose that in a domain we have
D
documents
(bottom, Figure 2) like program text, manuals, etc.,
that contain a total of
A
attributes
(middle, Figure 2) to describe
P
problems (top, Figure 2).
If any of these is large, then MLP is economical,
but for different reasons.
P*D
solutions are generated,
each of which is proportional to
A,
making a complete solution
proportional to
P*D*A .
Using traditional methods, the cost of developing
P*D
documents is proportional to
P*D*A.
Using MLP,
the cost is
D
times the cost
(Ct)
of developing templates for each document type,
D*Ct,
plus
P
times the cost
(Cp)
of describing the attributes of each problem,
P*Cp.
Both these have sizes proportional to
A,
the number of attributes,
so the total cost under MLP is
(D*Ct + P*Cp)*A.
In short, a multiplicative function has been replaced with an additive function
with larger factors for each addend.
Another way of appreciating at the benefits of MLP is
to note that:
Thus far, I have only discussed the initial cost of MLP,
which for domains with few required solutions,
is higher than traditional methods.
The cost/benefit analysis for maintenance is different,
and it should be addressed because,
as discussed in software engineering texts like
Zelkowitz, et al (1979),
Boehm (1981),
and
Fairley (1985),
the major cost in software is in maintenance.
Consider the cost of changing
an attribute of a problem,
a simple example of which might be to change the default value
and type of some user interface variable (e.g., a program option).
In the program source code,
we have to change at least one constant definition,
one type declaration,
type conversions (string format to the data type and back),
and perhaps also some comments.
In the documentation,
this information must be propagated throughout all documents,
where the use of symbolic constants is less likely.
In short, a small change that can be described with a couple of statements
has turned into an hour of uninspiring and probably error-prone busy-work.
Now consider the cost of changing the format of a screen display,
in a system that has, say, hundreds of screens.
In the MLP case, the change is made in one place
and the result is propagated throughout the system
with the major cost being computer time, not human time.
The change is made uniformly, and the need for retesting
is minimal compared to the tedious screen-by-screen tweaking
and viewing by human labor.
The benefits of MLP to the maintenance stage of the software lifecycle
are often overwhelming, as shown in these examples,
and as experienced in the IFS interface to the S statistical system
(Perlman, 1983),
which involved three target solutions
(IFS user interface, long manual, and short reference)
for over 300 problems.
Multilingual programming is a method in which
The key concept in MLP is that there is one source
of information from which all representations are generated.
MLP aids programmer/writer productivity
by reducing the amount of repetitive work that must be done
by skilled practitioners and by multiplying that effort.
MLP supports standards by using algorithmic generators
yet provides flexibility for even large systems because
changes are centralized in the database descriptions and in
the text generators.
The flexibility feature is especially useful in fuzzy areas
like user interface development where terms like
iterative design
and
rapid prototyping
are euphemisms for
We don't know what we're doing so we'll try something and work from there.
To develop high quality software,
we must be willing to plan to coordinate all parts of software products:
specifications, code, comments, user interface, online documentation,
error messages, short and long user manuals, and so on.
With a multilingual programming strategy,
accuracy, consistency, flexibility, and economy
are by-products of acknowledging the need for coordination.
TYPE COMMENT
FUNCTION sqrt double square root
ARGUMENTS
x double must be non-negative
and be based on some
troff
formatting macros (defined elsewhere) like:
.FN "sqrt" "x" "double" "square root"
.AG "x" "double" "must be non-negative"
The idiomatic templates for each language abstract the parts that
remain constant across uses.
Note that they contain the same information plugged into different,
but corresponding slots.
C:
/* purpose */
type function (arguments)
type argument; /* comment */
troff:
.FN "function" "arguments" "type" "purpose"
.AG "argument" "type" "comment"
Without a convention,
there is no way
to determine the referents of the comments.
Enforcement of the convention is difficult if the convention is not
supported with tools.
Tools supporting different types of comments and source code parsing
are still impractical in large projects because
of the need for coordination with other texts like printed documentation.
Database of Attributes
function = sqrt
purpose = square root
type = double
argument = x
type = double
comment = must be non-negative
and put into a database with two relations,
one for functions and one for arguments.
This information is target-language independent,
somewhat
object oriented,
implying that a person does not need to know the syntax of
any
language to program or write documentation
when programming multilingually.
Information needed for code generation or documentation
can be extracted and plugged into slots in templates.
Language specific syntax information is held in the templates.
Multiple Target Languages
Text Generators
Properties of Multilingual Programs
Generalization & Imagination
By the aid of symbolism,
we can make transitions in reasoning almost mechanically
by the eye,
which otherwise would call upon higher faculties of the brain.
By relieving the brain of all unnecessary work,
a good notation sets it free to concentrate on more advanced problems.
By parameterizing problems by analysis,
a notation is established,
and our ability to see new relationships
and form new syntheses is enhanced.
Flexibility and Resilience to Change
Accuracy and Consistency
Economy of Expression
Discussion
Choosing the Appropriate Focus
Multiple Views of Programs
Natural Language
Cost/Benefit Analysis
Development Cost/Benefit Analysis
By
free
I mean that the cost in human effort is small,
although the cost in computer resources may be large.
The larger
P
or
D
get, the larger the multiplicative factor of the benefit of MLP.
If
P
or
D
is small,
then MLP may not be worth the trouble
of learning and using the method.
If
P,
the number of problems, is large,
then MLP provides flexibility for change and abbreviation.
If
A,
the number of attributes, is large,
then MLP aids
possibilities for generalization,
flexibility for change,
and accuracy.
If
D,
the number of documents, is large,
then we aid the accuracy of the documents,
and help reduce human effort by abbreviation.
Maintenance Cost/Benefit Analysis
Summary and Conclusions
We always do the analysis in understanding a problem,
but with MLP it is explicit enough to be in database records.
The synthesis, if done by traditional human labor, is less regular;
documents, on-line help, or error checking
are often lacking and
sometimes missing because of laziness or forgetfulness or incompetence.
References